

Künstliche Intelligenz ist längst nicht mehr nur ein Thema für große Rechenzentren oder Cloud-Dienste. Immer mehr Anwender experimentieren damit, Sprachmodelle auf eigener Hardware laufen zu lassen – sei es aus Neugier, aus Datenschutzgründen oder einfach, um die Technik besser zu verstehen. Genau diese Gründe trieben mich um, es doch mal auf meinem kleine NAS Server zuhause auszuprobieren.
Auf meinem UGREEN NAS DXP 4800 Plus habe ich die Software Ollama installiert, die KI-Sprachmodelle lokal ausführt, sowie die Weboberfläche OpenWebUI, über die sich die Modelle komfortabel nutzen lassen. Der folgende Beitrag beschreibt, wie ich dabei vorgegangen bin, welche Stolpersteine es gibt und warum man das Ganze eher als Experiment denn als produktiven Einsatz betrachten sollte.
Inhalt
Die Hardware für das Ollama Experiment: UGREEN NAS DXP 4800 Plus
Das DXP 4800 Plus ist eigentlich ein klassischer Allround-NAS-Server, gedacht für Datenspeicherung, Medienverwaltung und als private Cloud. Für KI-Modelle ist es von der Hardware her naturgemäß nicht ausgelegt. Dennoch wollte ich sehen, wie weit man damit kommt.
Die technischen Eckdaten meines Systems sehen so aus:
- Modell: UGREEN NASync DXP 4800 Plus
- CPU: Intel Pentium Gold 8505 (12. Generation, x86)
- Kerne/Threads: 5 Kerne (1 P-Core bis 4,4 GHz, 4 E-Cores bis 3,3 GHz), 6 Threads
- RAM: 8 GB DDR5-4800, bei mir auf 40 GB erweitert
- Systemlaufwerk: SSD 128 GB (nicht eMMC) :
- Festplatteneinschübe: 4 × SATA; zusätzlich 2 × M.2 NVMe (PCIe 4.0),, bei mir mit 4x8TB und einer 1TB SSD bestückt.
Gerade die SSD ist ein wichtiger Punkt: Dort laufen alle Container, damit die Anwendungen nicht ständig die HDDs aus dem Hibernation-Modus reißen und die Platten unruhig werden.
Was fehlt: Eine schnelle NVIDIA GPU, mit der die KI via Ollama um einiges flotter arbeiten könnte.

Anzeige
Vorbereitung: Docker-Umgebung einrichten
Ollama und OpenWebUI lassen sich als Container installieren. UGREEN liefert zwar eine eigene Docker-App mit, ich habe mich aber für Portainer entschieden, weil die Oberfläche flexibler ist und ich damit besser arbeiten kann. Eine sehr hilfreiche Anleitung zur Installation von Portainer auf dem UGREEN NAS findet sich bei Marius Bogdan auf mariushosting.com.
Wer möchte, kann natürlich auch direkt die mitgelieferte Docker-App von UGOS verwenden. Beide Wege führen zum Ziel – entscheidend ist am Ende die Ausführung der Compose-Datei, die die Container startet.
Bevor wir mit dem eigentlichen Setup beginnen, müssen im Docker-Verzeichnis auf dem NAS zwei Ordner angelegt werden. Bei mir liegt der Docker-Ordner auf dem SSD-Volume /volume2/docker/. Dort habe ich folgende Unterverzeichnisse erstellt:
ollama_dataopenwebui_data
Wichtig: Nur Kleinbuchstaben verwenden, da ist Linux streng!
Installation der Container
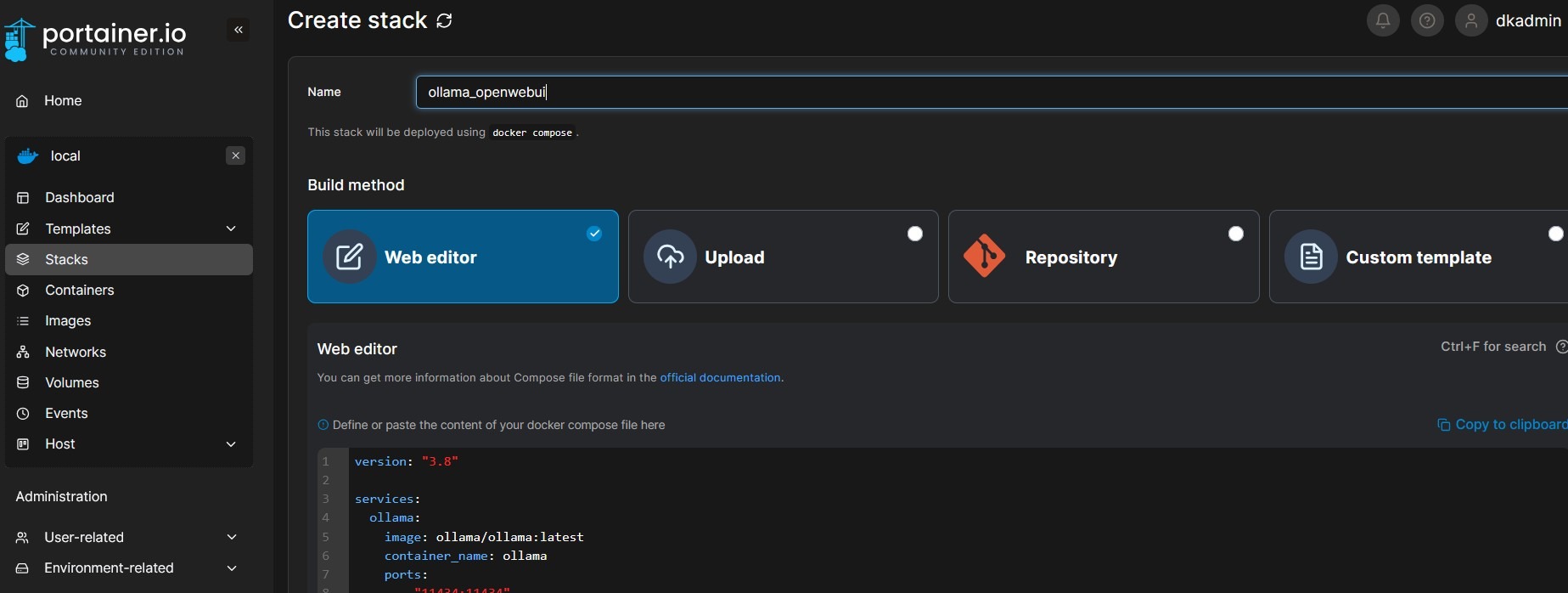
Nach dem Login in Portainer (oder alternativ in der Docker-App von UGOS) lege ich einen neuen Stack an. In UGOS heißt die Funktion „Projekt“. Diesem Stack gebe ich einen passenden Namen, etwa ollama_openwebui.
Anschließend füge ich den Compose-Code ein, mit dem Docker die richtigen Images zieht und konfiguriert:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- /volume2/docker/ollama_data:/root/.ollama
#deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 2
# capabilities: [gpu]
environment:
- OLLAMA_HOST=0.0.0.0:11434
restart: always
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
volumes:
- /volume2/docker/openwebui_data:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
extra_hosts:
- "host.docker.internal:host-gateway"
restart: always
volumes:
ollama_data:
openwebui_data:
Die hier angegebenen Pfade zu den Volumes (rot dargestellt) müssen jeweils an die eigene NAS-Konfiguration angepasst werden. Bei mir liegt das Docker-Verzeichnis auf der internen SSD, dem Volume 2. Die GPU-spezifischen Kommandos habe ich bewusst auskommentiert, da das NAS keine NVIDIA-Grafikkarte besitzt. Solltest Du den Stack auf einem anderen System mit NVIDIA GPU installieren, entferne die vorangestellten #.
Nach dem Einfügen des Codes einfach auf „Deploy“ klicken (in Portainer) bzw. „Bereitstellen“ (in der UGOS Docker-App). Dann heißt es warten: Docker lädt die Images herunter, und je nach Internetverbindung und Systemgeschwindigkeit kann das eine Weile dauern.
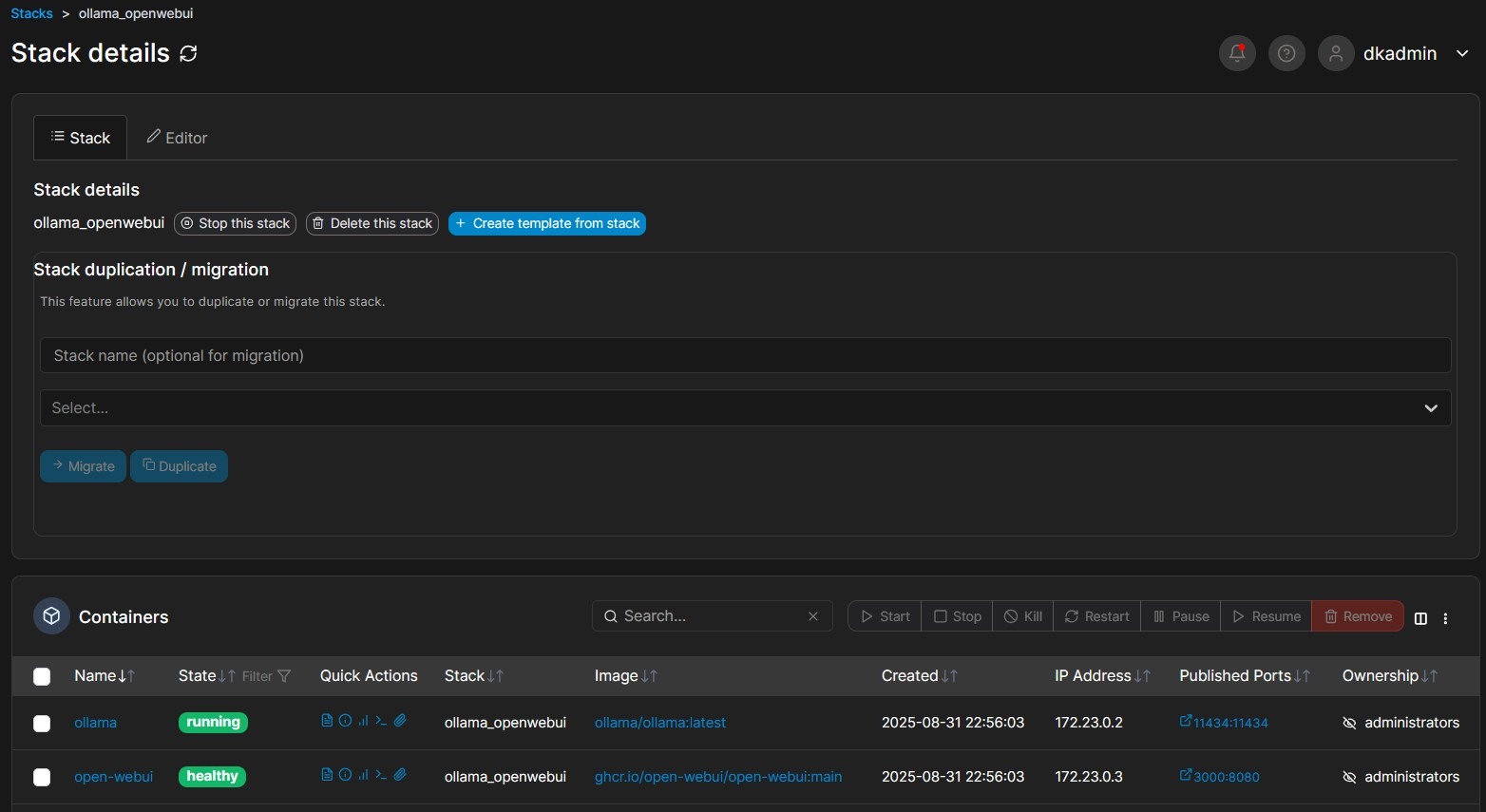
War das Deployment erfolgreich, werden die Container automatisch gestartet und sollten in der Übersicht nun als ollama und open_webui als laufende Container sichtbar sein.
Erste Schritte in OpenWebUI
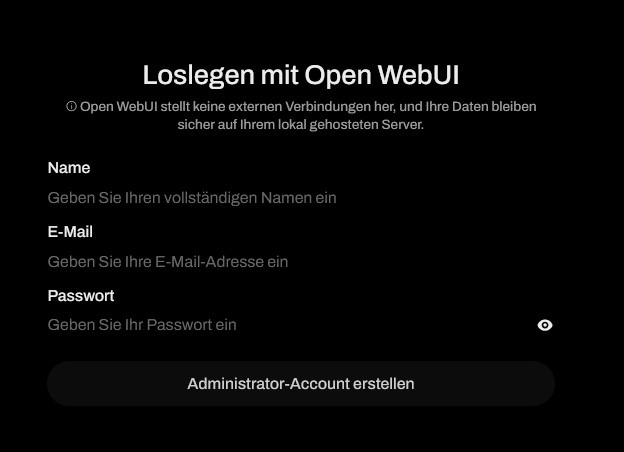
Die Weboberfläche erreicht man über die IP-Adresse des NAS und den Port 3000, zum Beispiel 192.168.178.96:3000. Beim ersten Aufruf muss ein Admin-Account angelegt werden. Dazu vergibt man Benutzername, E-Mail-Adresse und Passwort. Achtung: Es gibt kein Kontrollfeld für das Passwort, also genau hinschauen!
Nach dem Login präsentiert sich die Oberfläche ähnlich wie von gängigen KI-Chatlösungen gewohnt. Allerdings ist noch kein Sprachmodell installiert – ohne das geht natürlich nichts.
Sprachmodelle auswählen und installieren
Über das Nutzermenü oben rechts gelangt man in den Einstellungsbereich.
Der Administrationsbereich versteckt sich unten links im Bild
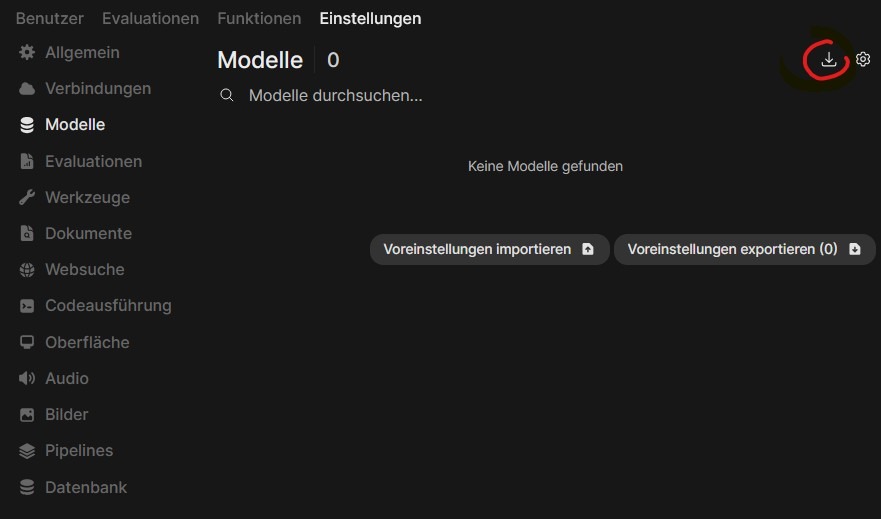
Den Menüpunkt zum Herunterladen und Verwalten der Sprachmodelle findet sich dann wieder leicht versteckt oben rechts (hier rot eingekreist).
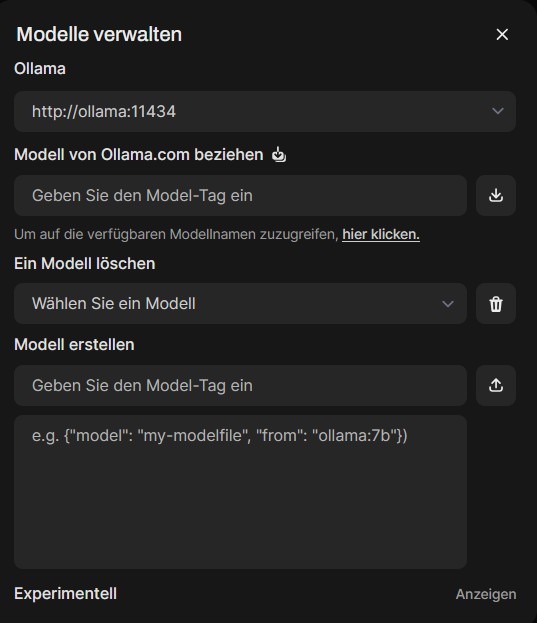
Nun gilt es, ein Sprachmodell von Ollama zu beziehen. Dazu muss da exakte Model-Tag eingegeben werden. Ein Link zur Übersicht aller verfügbaren Modelle findet sich direkt in der Oberfläche untere dem Eingabefeld oder online unter ollama.com/library. Für meinen ersten Test habe ich mistral:latest verwendet.
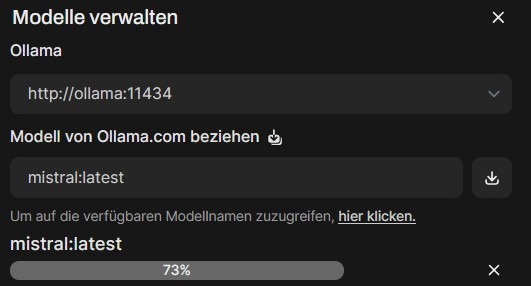
Hier ist allerdings Vorsicht geboten: Große Modelle können das NAS überfordern. Besser eignen sich kleinere, ressourcenschonende Modelle oder spezielle Edge-Varianten. Aber wie so oft gilt: Probieren geht über Studieren. Die Größe der jeweiligen Modelle wird in der Übersicht auf ollama.com gut dargestellt.
Fazit: Es läuft – mit Abstrichen
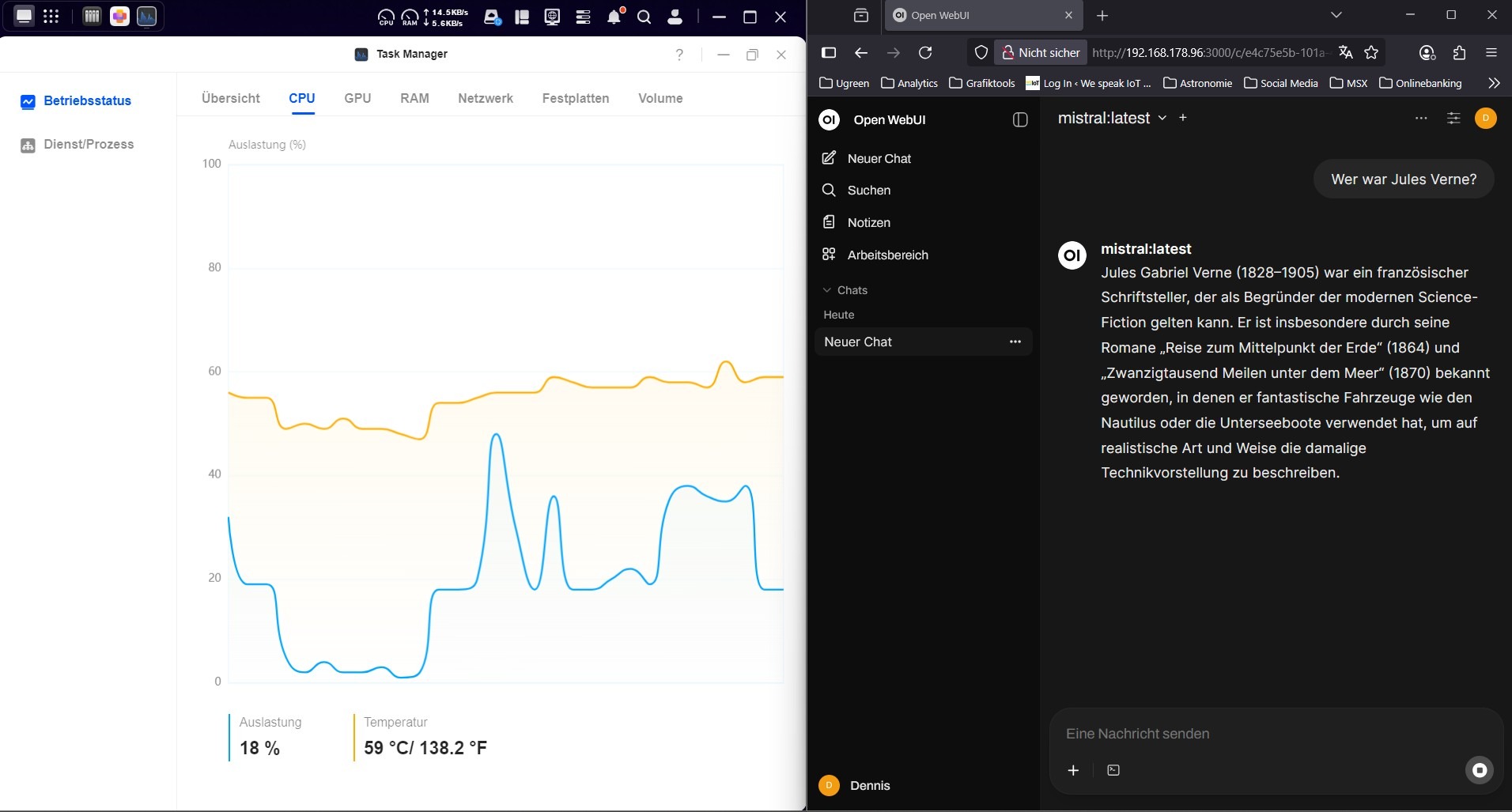
Sobald das erste Modell installiert ist, kann man direkt mit Anfragen loslegen. In meinem Fall habe ich eine kleine Testfrage zu Jules Verne gestellt. Das NAS hat diese Aufgabe gemeistert, ohne gleich in die Knie zu gehen – die CPU-Auslastung war allerdings deutlich sichtbar.
Wie schnell ist die KI auf dem UGREEN NAS?
Um die Verarabeitungsgeschwindigkeit eines Sprachmodells (LMM) zu bewerten, misst man diese in Token pro Sekunde. Dabei bezeichnet ein Token ein Textbaustein (z. B. ein Wort oder Wortteil), den das Modell liest oder erzeugt. Die Kennzahl zeigt also, wie viele solcher Tokens das Modell pro Sekunde generieren oder verarbeiten kann – und ist damit ein direktes Maß für die Performance auf einem bestimmten Server.
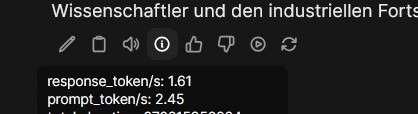
Mit OpenWebUI erscheinen unter jeder Antwort kleine Icons, darunter ein Informations-Icon, ein eingekreistes „i“. Dort lassen sich zu jeder Antwort die Token/S ablesen. Mein NAS schaffte hier mit Mistral rund 1,5 Antwort-Token pro Sekunde und rund 2,5 Prompt-Token pro Sekunde. Mit DeepSeek R1 waren es zumindest 4,4 Antwort-Token/s und mit phi3 rund 2,7 Token/s, moondream kam auf 5,8 Token/s.
Zum Vergleich: Auf meinem anderen Rechner mit 32 GB RAM, Intel i7 K12700K Prozessor und NVIDIA RTX 4060 GPU mit 8 GB liegt dieser Wert auf einer Linux Installation bei rund 45 Response-Token pro Sekunde und mehr, je nach Anfrage und Sprachmodell. Da macht das Schwätzchen mit der KI dann schon mehr Spaß.
Aber auch hier muss man einfach ausprobieren. Kleinere Sprachmodelle z.B. für Edge-Anwendungen (also auf leistungsreduzierten Systemen) können durchaus größere Werte auf dem NAS erzielen.
Man sollte sich also bewusst machen: Ein NAS dieser Klasse ist kein Ersatz für einen dedizierten KI-Server oder eine GPU-gestützte Workstation. Aber als Experiment, Lernprojekt oder Spielwiese ist es allemal spannend. Auch muss man Ollama nicht mit der Chatoberfläche benutzen. Es gibt viele Anwendungen, in die sich kleinere Sprachmodelle integrieren lassen. Ein Beispiel ist die Open Source Dokumentenverwaltung paperless ngx, die sich mit Ollama und paperless AI noch viel „smarter“ machen lässt.
Viel Spaß beim Ausprobieren!
这篇文章写得真清楚!跟着步骤在NAS上装Ollama和OpenWebUI简直太好玩了,但确实感觉性能和我的电脑没法比。不过用小模型玩玩还是很有意思的,特别是看到token/s的对比,NAS也能派上用场!😄
Allow me to translate (via deepl.com): This article is so clear! Following the steps to install Ollama and OpenWebUI on my NAS was a blast, though I must admit the performance doesn’t quite match my desktop. Still, it’s fun to tinker with smaller models, especially seeing the token/s comparison—turns out my NAS can still be useful! 😄
Hi Denis,
wäre es möglich das man dem webui sagt „für Model xyz (z.b. deepseek) nutze nicht dein local llm sondern : ?“ also das man quasi seinen dicken pc für krasse Modelle verwenden kann
Hi Tom,
gute Frage. Das Problem ist aber, dass die Sprachmodelle in Ollama laufen, die Du dann in der Open WebUI auswählst. Soll dann Sprachmodell X von einem leistungsfähigeren Rechner verarbeitet werden, müsste auch Ollama dort laufen. Du müsstest also innerhalb der WebUI Ollama wechseln können. Ich glaube, das ist so nicht möglich. Dann wäre wohl die Installation einer eigenen Ollama/OpenWebUI Umgebung auf dem großen Rechner gleich angesagt.
Hallo Dennis,
vielen Dank für deinen Beitrag zu Ollama auf dem Ugreen DXP 4800 plus – ich kann genau das selbe Setup von daher super hilfreich.
Ich habe gesehen, dass es angepasste Versionen von ollama für igpu gibt, die GPU-Beschleunigung über die integrierte Intel-Grafik (z. B. via ollama-ipex oder ollama-webui-intel) unterstützen.
Dazu gibt’s ein paar angepasste GitHub Repos auch mit dockerfiles usw.
Hast du das vielleicht schon ausprobiert oder planst du, das mal zu testen? Mich würde interessieren, ob sich damit in der Praxis (auf derselben Hardware) wirklich ein Leistungsgewinn ergibt.
Viele Grüße
Chris
Hi Chris,
danke für Deinen Hinweis mit den angepassten Versionen. Das klingt interessant, wusste ich bis dato noch nicht. Das schaue ich mir mal an!